TSS assembly pipeline for HsNC_EPDnew_001
Introduction
This document provides a technical description of the transcription start site assembly pipeline that was used to generate EPDnewNC version 001 for H. sapiens.Source Data
Promoter collection:
| Name | Genome Assembly | Promoters | Genes | PMID | Access data | ||
|---|---|---|---|---|---|---|---|
| HGNC | Dec 2013 GRCh38/hg38 | 8685 | 3496 | 30304474 | SOURCE | DOC | DATA |
Experimental data:
| Name | Type | Samples | Tags | PMID | Access data | ||
|---|---|---|---|---|---|---|---|
| FANTOM5 | CAGE | 941 | 18,244,201,540 | 24670764 | SOURCE | DOC | DATA |
| ENCODE | CAGE | 145 | 7,134,200,060 | 22955620 | SOURCE | DOC | DATA |
| ENCODE | RAMPAGE | 225 | 13,540,041,874 | 22936248 | SOURCE | DOC | DATA |
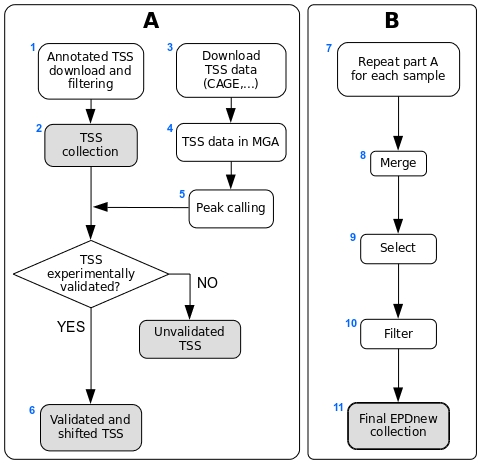
Assembly pipeline overview
|
Description of procedures and intermediate data files
1. Download of annotated promoters
A list of non-coding RNA genes was downloaded from HGNC BioMart. Genes were kept if the locus type was either antisense or long intergenic non-coding RNA. As we could not retrieve the coordinates directly from HGNC, we used Ensembl BioMart and the Ensembl Gene ID to get them wherever possible, and RefSeq otherwise. Genes which we could not get coordinates for were discarded. All transcripts associated with any given gene were considered, but those with the same TSS position were merged under a common transcript ID. The resulting list contained 8685 TSSs covering 3496 genes.
2. HGNC TSS collection
The HGNC TSS collection is stored as a tab-delimited text file conforming to the SGA format. The six fields in the file contain the following information:
- NCBI/RefSeq chromosome id
- "TSS"
- position
- strand ("+" or "-")
- "1"
- Gene name.
3. Download of TSS mapping data
TSS mapping data (CAGE and RAMPAGE) was downloaded from UCSC ftp site and FANTOM5 http site (see links above). The source files are in BAM format mapped on the hg19 genome assembly. Samples were lifted-over to the hg38 genome assembly using the liftOver tool. The complete list of files can be found here for ENCODE (or here for RAMPAGE) and here for FANTOM5. BAM files were converted into BED files with the bamToBed program. Files were kept and analyzed individually.
4. MGA archive
The compressed versions of these files are available from the MGA archive (see links above).
5. Peak calling
Peak calling for each individual CAGE and RAMPAGE data file was carried out using our ChIP-Peak online tool with the following parameters:- window width = 1
- vicinity range = 200
- peak refine = N
- count cutoff = 9999999
- threshold = 5
6. HGNC TSS validation by TSS mapping data
Each sample was processed in a pipeline aiming at validating TSSs with CAGE/RAMPAGE peaks. An HGNC TSS was experimentally confirmed if a peak lied in a window of 50 bp around it. The validated TSS was then shifted to the nearest base with the higher tag density.
7. Sample-specific promoter collection
Each sample in the dataset was used to generate a separate promoter collection. The same promoter could be validated in multiple samples and could have different start sites in different samples. To avoid redundancy, the individual collections were used as input for an additional step in the analysis (see part B in the figure above).
8. Merging collections
All sample-specific promoter collections were merged into a unique file and further analyzed. A promoter was retained in the list only if validated by at least 3 samples. Promoters validated by multiple samples may have their start site set on a broader region rather than a single position. For each transcript, we thus selected the position validated by the largest number of samples as the "true" TSS.
9. Further TSS selection
We used our ChIP-Peak online tool as above but with a vicinity of 150 and a threshold of 1, in order to retain the single most expressed promoter in each promoter "cluster".
10. Filtering
We finally applied an additional filtering on relative expression, keeping only promoters whose expression represents at least 10% of the associated gene's total expression. We also decided to limit the number of promoters per gene to 5.